Writing
All Posts
Deep dives into AI, backend engineering, and development
Distributed Transactions in Microservices: Why Consistency Gets Complicated Fast
Distributed transactions sound straightforward in theory: multiple services should either succeed together or fail together. In practice, things become messy very quickly. Network failures, retries, partial commits, and service crashes make consistency one of the hardest problems in distributed systems. This post takes a deep dive into distributed transactions, why traditional approaches struggle in microservices, and how Two-Phase Commit and Saga patterns behave in real production systems.
.png?width=800&height=450&quality=68&format=origin)
Model Context Protocol (MCP): Designing Reliable Tool-Driven AI Systems at Scale
Read the full post for details.
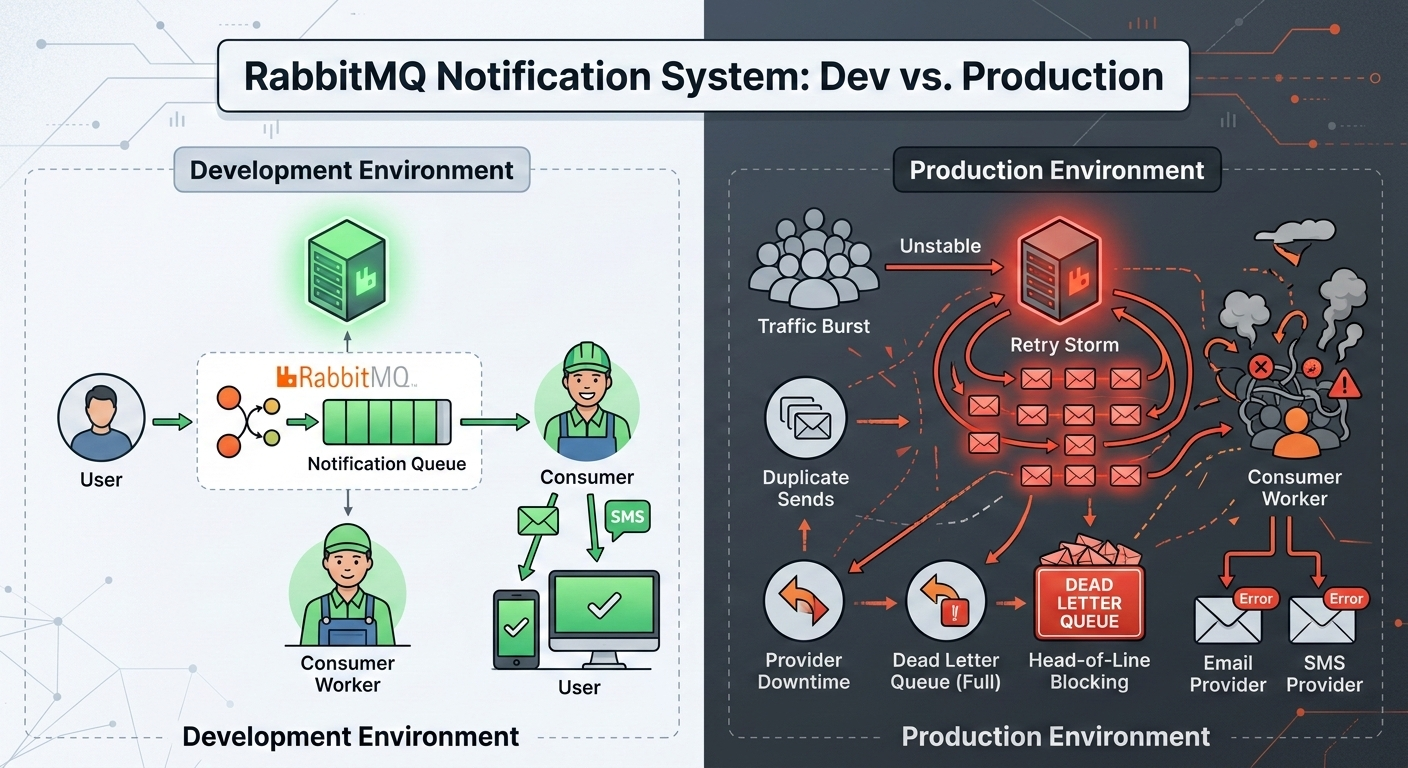
When RabbitMQ Notifications Go Wrong: The Production Failures No One Warns You About
Sending notifications with RabbitMQ looks simple — publish a message, consume it, send email or push. But under real traffic, retry storms, duplicate sends, ordering issues, and dead-letter queues start appearing. This post breaks down what actually goes wrong and how production systems handle it.</p>
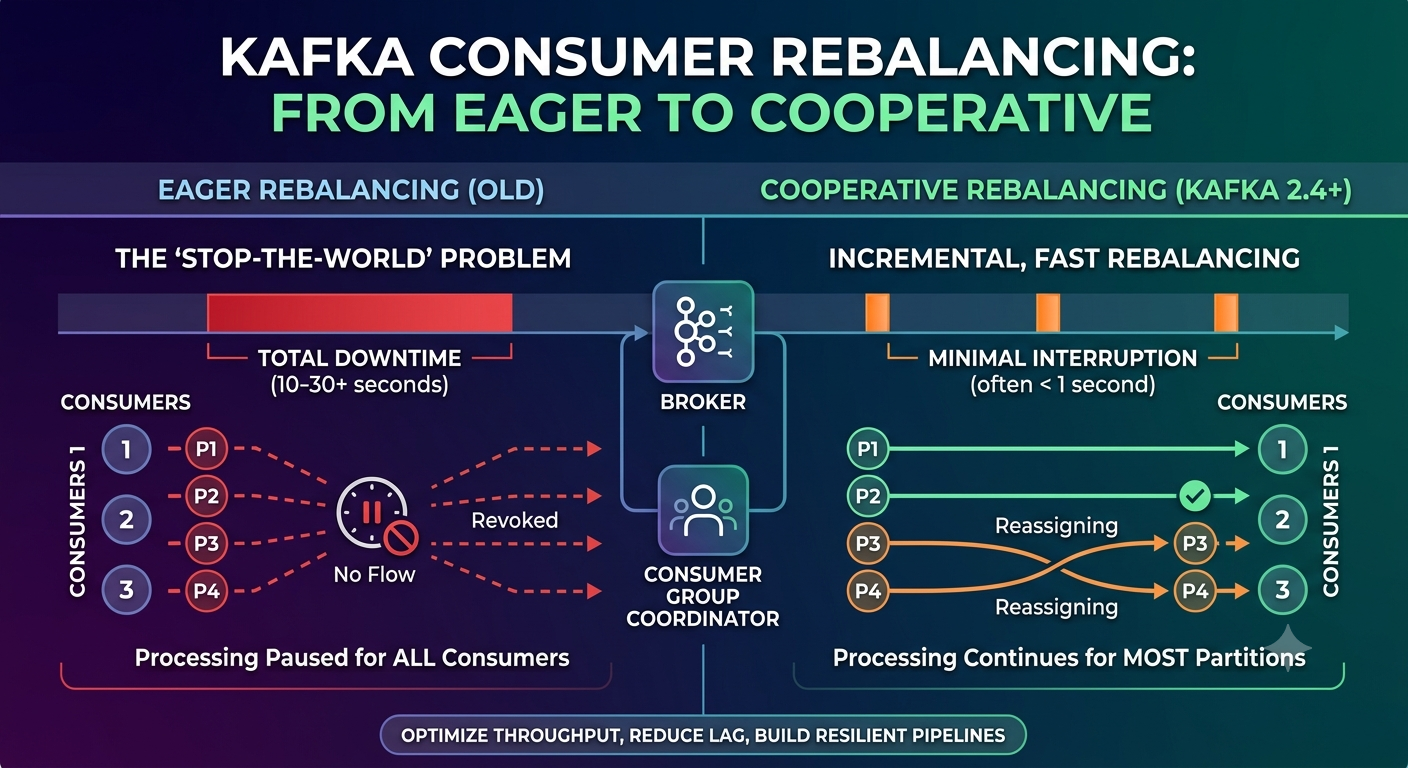
Kafka Consumer Rebalancing: From Eager to Cooperative – Heart of Stream Processing
Consumer rebalancing is the most misunderstood and underestimated component of Apache Kafka. A single misconfigured timeout can bring a streaming pipeline to its knees. This post dissects the rebalancing protocol – from the eager, stop‑the‑world days to today’s incremental, cooperative approach. You’ll learn what happens inside the consumer group coordinator, why rebalance storms occur, and how to tune for resilience. Written for engineers who run Kafka in production.
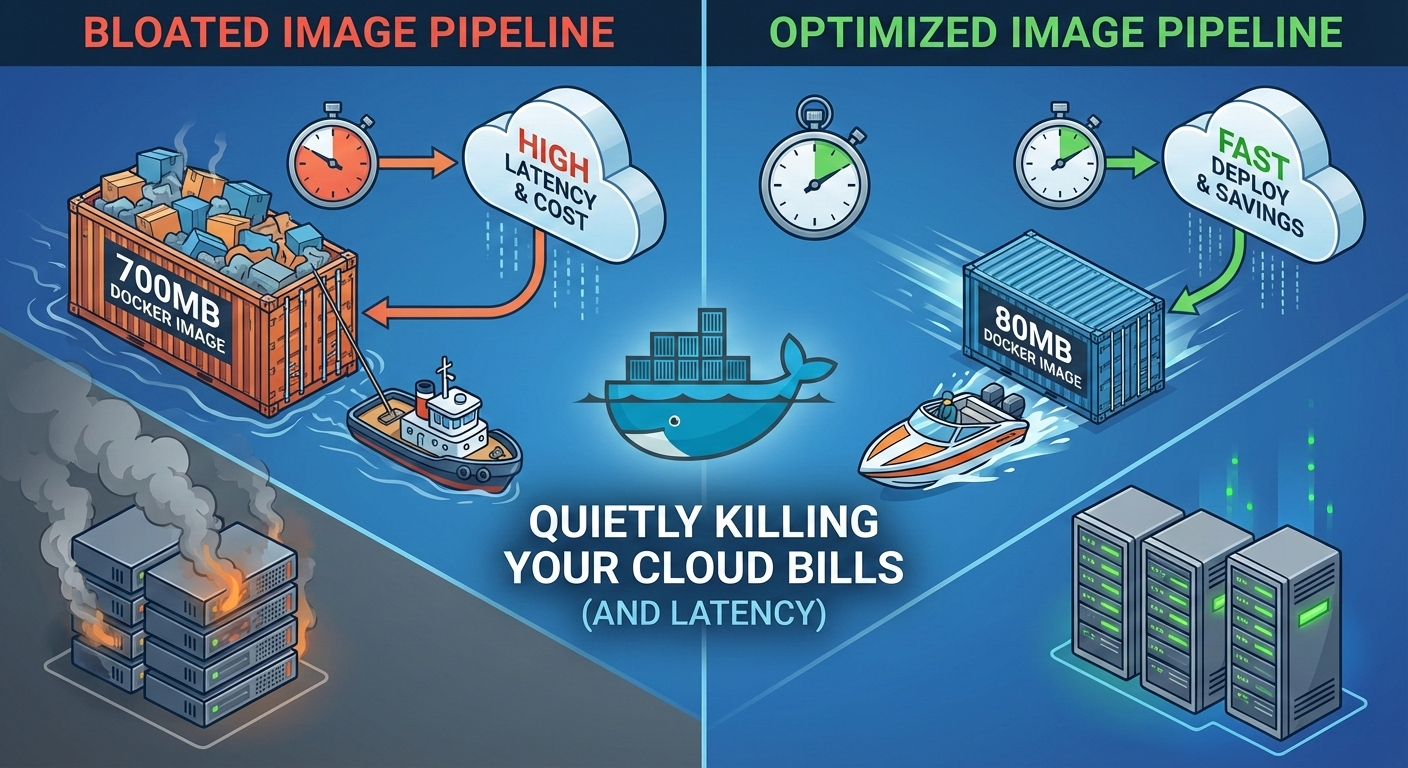
Why Your Docker Images Are Quietly Killing Your Cloud Bills (and Latency)
Read the full post for details.

Making Voice AI Truly Real-Time: Reducing Latency in Production Systems
Read the full post for details.
Showing 1–6 of 11 posts